참석 후기 NAVER AI Colloquium (채동규/이연창/배홍균/홍석진/서나윤/서동혁)


2018 NAVER AI Colloquium는 올해 3회째를 맞은 행사로, 검색, 추천, 자연어 처리, 비전, 모빌리티,로보틱스 등 12개 세션의 32개 아젠다 / 23개 포스터&데모 세션으로 구성되었습니다. 작년과 다르게 올해에는 네이버 연구진들 뿐만 아니라 네이버와 산학 연구를 수행하는 AI 분야 교수 및 대학원생들의 발표 또한 진행되었습니다. 김상욱 교수님께서도 recommendation 세션에서 ‘Uninteresting items - A Novel Concept Boosting the Accuracy in Recommendation Systems’ 라는 주제로 발표를 하셨습니다.
본 행사에는 우리 연구실의 채동규, 이연창, 배홍균, 홍석진, 서나윤, 서동혁 학생이 참석하였습니다.
[채동규]
네이버 AI 콜로퀴움을 통해서 딥러닝과 관련된 국내의 최신 연구동향을 접할 수 있어서 큰 도움이 되었습니다. 특히 카이스트에서 진행중인 large scale deep learning과 관련된 여러 연구 이슈와 이를 해결하는 과정에서 많은 것을 배웠습니다. UNIST의 해석 가능한 인공지능 연구도 인상깊어 보였습니다. 네이버에서 추천과 검색 기술을 실제 서비스로 제공하기 위해서는 학계에서 고민하지 않는 다른 많은 요소를 함께 고려해서 기술을 개발하는 부분도 새롭게 배울 수 있었습니다.
좋은 세미나에 참석할 기회를 주신 교수님께 감사드립니다. 세미나를 통해 얻은 여러 지식들을 제 연구 진행에 잘 적용해서 좋은 성과로 만들어보도록 하겠습니다.
[이연창]
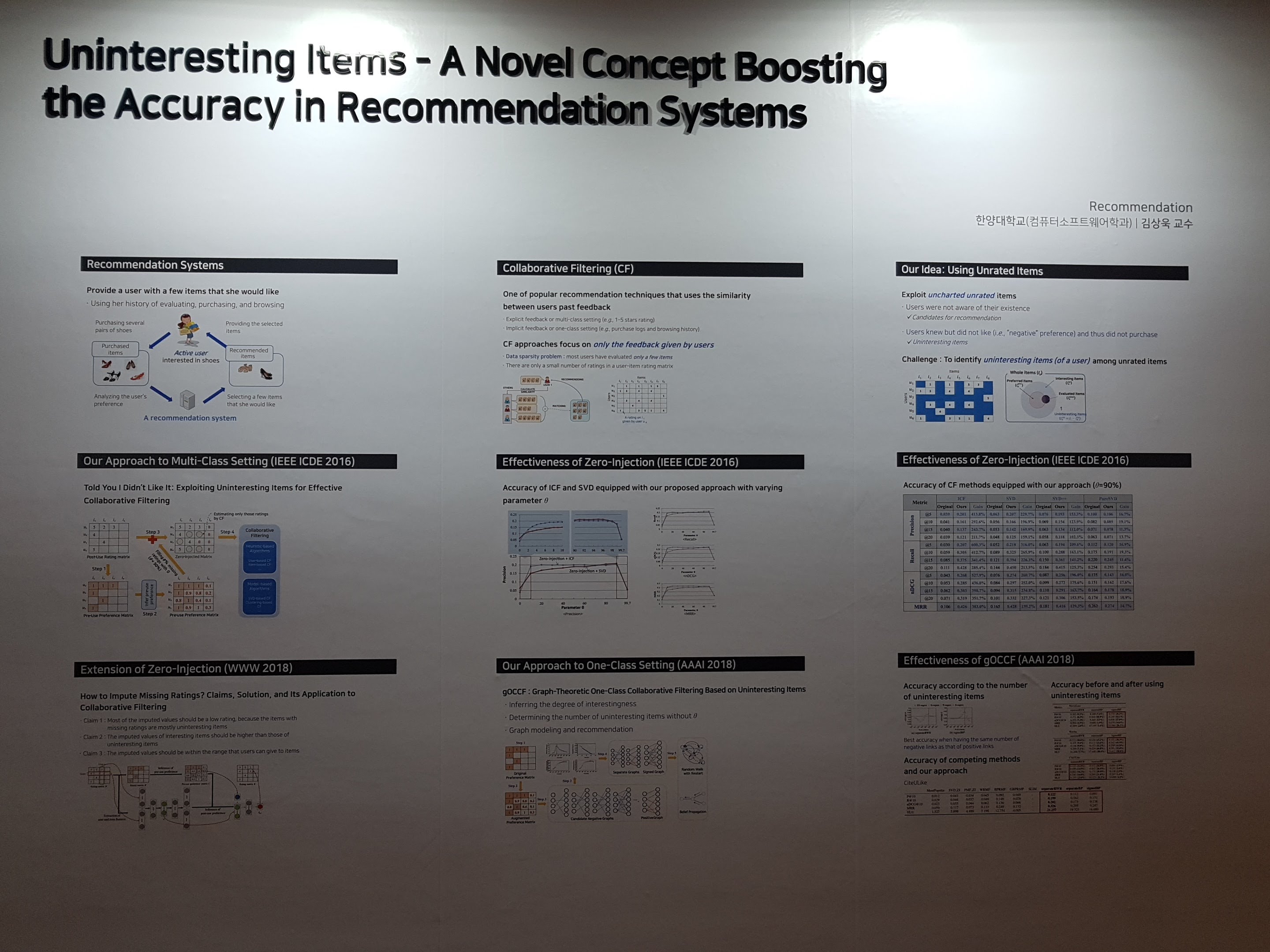
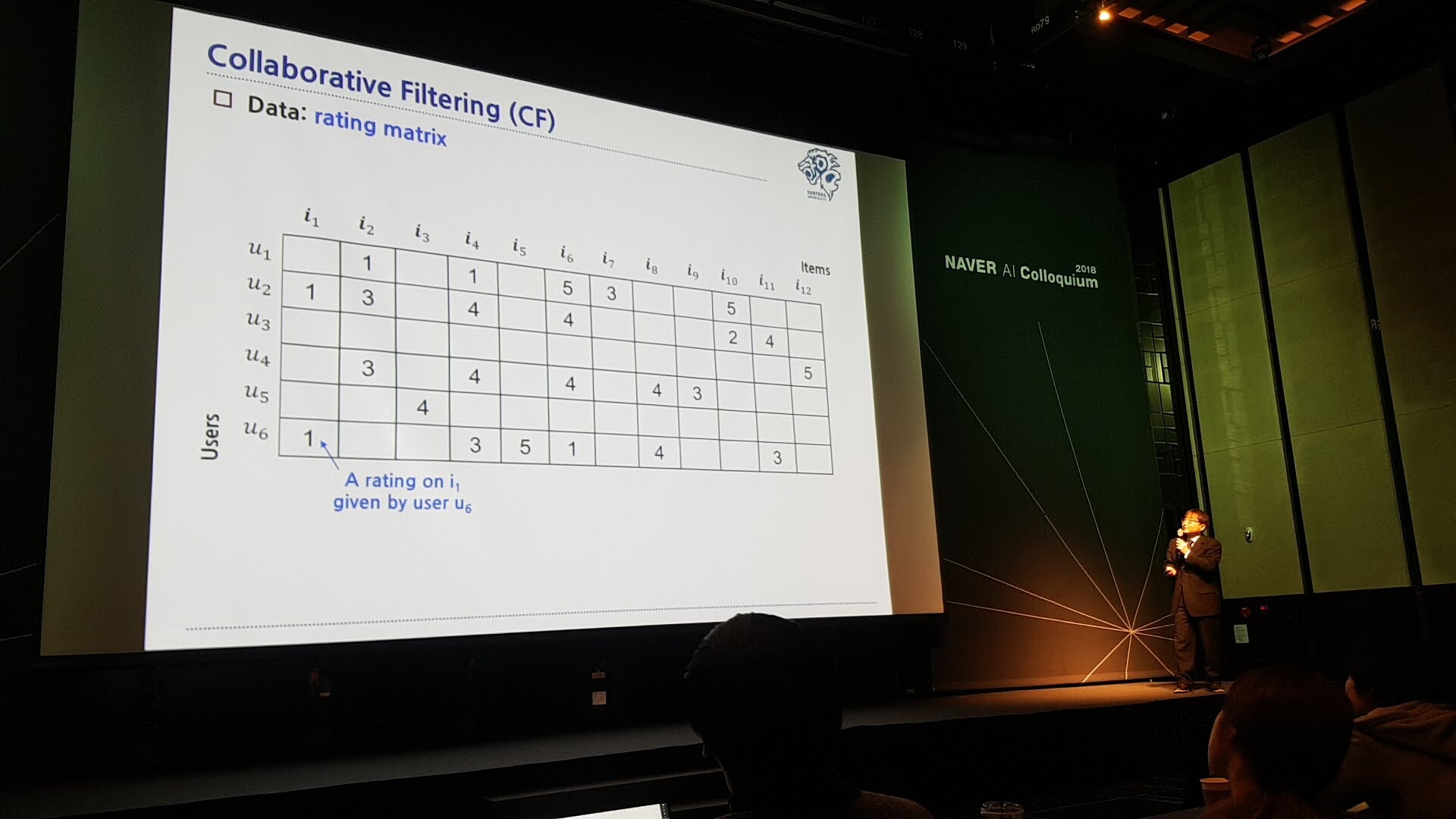
네이버 ai 콜로키움은 작년에 이어 두 번째로 참석하는 행사입니다. 현재 저희 연구실과 네이버가 추천 관련 산학 과제를 수행 중이어서, 올해 행사에서는 교수님의 구두 발표와 더불어 포스터 세션에서 포스터 발표를 할 기회가 주어졌습니다. 각 세션이 끝나는 쉬는 시간들과 점심 시간마다 포스터 세션이 진행되어, 많은 행사 참석자들과 교류할 수 있는 시간이었습니다. 저희 포스터에 들려주신 많은 분들이 저희 연구를 재밌게 생각하시고 관심을 가져 주셔서 뿌듯한 마음도 들었습니다.
포스터 세션이 진행되지 않는 시간들에는 관심 분야 세션장에서 다양한 AI 기술들의 발표를 들을 수 있었습니다. 여러 발표 중 네이버 최재걸 리더님께서 발표한 generative adversarial nets (GAN) 기반의 click models (제목: GANCM: Generative Adversarial Network Click Model)을 특히 흥미롭게 들었습니다. 해당 발표에서는 네이버 검색 엔진을 사용하는 가상의 users를 GAN을 이용하여 생성한 뒤, 해당 가상 users에게 어떠한 형태 (순서/디자인 등) 로 검색 결과를 제공할 때 가장 많은 clicks을 얻어낼 수 있을지를 분석한 결과를 보여주었습니다.
이번 행사를 통해 다양한 도메인에서 최신 ai 기술을 성공적으로 적용한 사례들을 종합적으로 파악할 수 있어 매우 의미있는 시간이었습니다. 끝으로 의미있는 행사에 참석할 수 있고, 또한 포스터 발표를 통해 다양한 연구자들과 교류할 수 있는 기회를 주신 김상욱 교수님께 감사드립니다.

[배홍균]
검색, 뉴스, 쇼핑 등 편리하고 익숙하게 사용 중이었던 네이버의 서비스에 생각보다도 다양한 AI 기술이 이미 적용되어 있었단 사실이 신선한 충격으로 다가왔던 시간이었습니다. 수많은 서로 다른 사용자들의 검색 의도, 클릭 패턴 등의 파악을 위하여 익숙한 이름의 AI 기법인 GAN, RNN 등이 사용되어지고 있다는 점은 무척 흥미로웠습니다. 아쉽게도 아직은 제가 AI 관련 배경 지식을 충분히 갖고 있진 못한 탓에, 세부적인 접목 방법 등을 바로 이해하는데에 있어선 조금 어려움이 따랐지만 네이버가 어떤 목적과 방향으로 AI 기술을 발전시켜 나가고자 하는지에 대해선 무리 없이 받아들일 수 있었습니다.
또한 ‘AI를 이용한 추천’ 섹션엔 다양한 강연들이 준비되어 있었는데, 추천 관련 연구를 하고 있는 입장에서 여러 아이디어들을 떠올려 볼 수 있었던 귀중한 시간들이었습니다. 네이버에서 제공하는 많은 종류의 서비스가 본질적으로 추천과 직, 간접적인 연관을 맺고 있다는 사실을 새삼 느끼며 무심코 지나쳤던 서비스 하나 하나에 대하여 더 관심 있게 살펴봐야겠다는 생각도 갖게 되었습니다.
생생한 기술의 현장을 체험할 수 있도록 기회 만들어주신 김상욱 교수님께 깊은 감사를 드립니다. 점점 더 자연스럽게 생활의 일부가 되어 갈 네이버의 서비스 또한 벌써부터 많이 기다려집니다.
[홍석진]
NAVER가 실제로 AI를 서비스에 어떤 방식으로 적용하는지 알 수 있는 좋은 시간이었습니다. 또한 네이버와 같이 산학협력하고 있는 연구실에서 어떤 연구를 진행하는지도 알 수 있었습니다.
그 가운데 트렌드를 반영하는 Dynamic Word Embedding model이 기억에 남았습니다. 연구하면서 워드 임베딩 모델을 사용할 기회가 있었는데, 이때 생각난 궁금증이 ‘시간이 지나면서 바뀌는 단어 간 의미적 유사도를 어떻게 동적으로 워드 임베딩 모델에 반영할 수 있을까?’ 였습니다. NAVER에서는 잘 학습된 워드 임베딩 모델에 최신뉴스 기사를 이용하여 뉴스기사에 함께 자주 나오는 토픽들을 서로 가깝게 워드 임베딩 공간상에 위치시킴으로써 워드 임베딩 모델이 현재 트렌드를 반영할 수 있도록 연구를 진행했습니다. 즉 ‘맥도날드’와 ‘햄버거병’이 최신 뉴스 기사에서 자주 함께 등장하면 두 단어가 임베딩 공간상에서 가깝게 위치하게 되는 방식입니다. 이 연구 이외에도 많은 NAVER의 연구에서 워드 임베딩 모델이 사용되는 것을 볼 수 있었습니다.
우리가 연구 및 개발하는 기술들이 실제 산업현장에서 어떻게 사용되는지 알 수 있는 좋은 기회였습니다. 참석할 수 있도록 배려해주신 김상욱 교수님께 감사드리고, 다음에도 비슷한 행사가 있으면 참석해보고 싶습니다.

[서나윤]
최근 인공지능 분야에서 다양한 성과를 내고 있는 네이버에서 어떤 연구를 하고 있는지 한 곳에서 소개받을 수 있는 의미 있는 자리였습니다. 참석함으로서 현업에서 서비스중인 기술과 더불어 네이버와 연구 중인 산학 연구실들의 인사이트를 다양하게 듣고 고민해볼 수 있었습니다.
인상 깊었던 아이디어는 Large scale deep learning 발표에서 소개된 “모델에서 실제로 사용되는 부분을 구분하여 모델 성능을 높이는 것”이었습니다. 이미지 데이터를 분류할 때 모델 내에서 이미지의 특징과 관계가 먼 부분은 비활성화해 관계있는 부분의 학습에 보다 집중하게 하거나, 관계있는 부분만을 그룹화해 해당 부분을 사용하게 하는 등의 방법을 알 수 있었습니다. 같이 소개된 데이터 간 공통된 특징은 공유하되 개별 클래스의 고유한 특징을 추가로 학습에 이용하는 메트릭 또한 흥미로웠습니다.
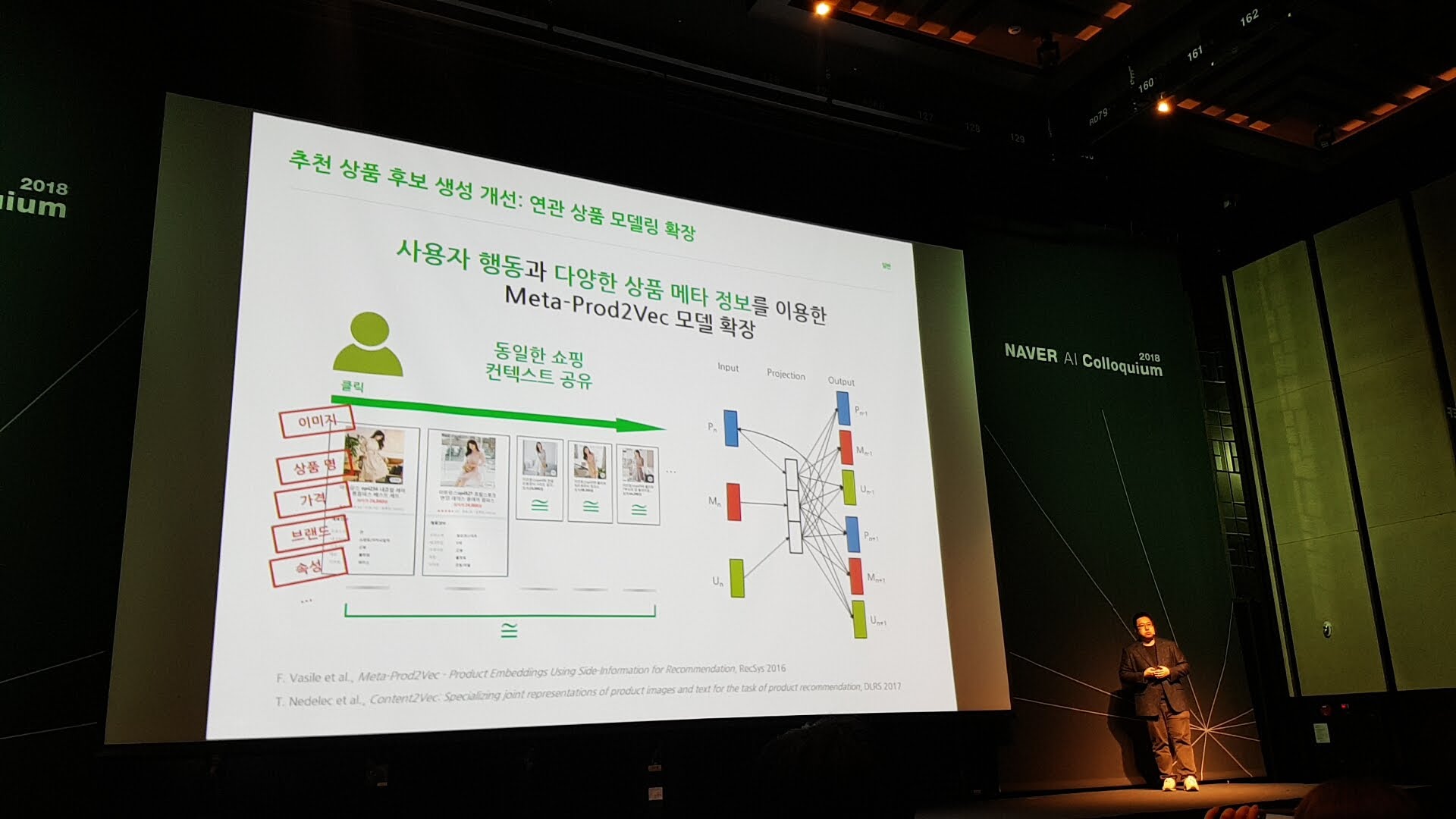
추천 세션에서는 주로 현업에서 해결 중인 문제들과 그 접근법이 인상 깊었습니다. 장소 추천 서비스에서는 TPO에 따라 가변적인 사용자의 입맛과 색이 강한 장소의 특징을 함께 아우를 수 있는 방법을 연구 중이었으며, 쇼핑 추천 서비스에서는 소비자의 의도를 정확히 파악하고 다양한 상품을 제공할 수 있도록 노력하고 있었습니다. 특히 쇼핑 추천에서 사용자가 선택한 아이템과 어울리는 코디 상품을 추천하는 데에 GAN을 통해 만든 ‘어울리는 제품’의 이미지를 활용하는 법을 연구 중인 부분에 관심이 갔습니다. 그밖에 아이템이 가진 내용과 아이템에 대한 사용자 반응을 두 개의 다른 모델을 이용해 하나의 임베딩으로 녹여낸 포스텍의 연구를 관심 있게 들었습니다.
참석을 통해 경험한 내용을 여러 연구에 적용해보고 싶어지도록 하는 좋은 행사였습니다. 앞으로도 현업과 연구의 최신 동향을 알 수 있는 이러한 세미나에 참석할 기회가 많았으면 하는 바람입니다. 훌륭한 행사에 참석할 수 있게 해주신 김상욱 교수님께 감사드립니다.
[서동혁]
Naver라는 회사가 AI라는 분야에 있어 어떤 세부분야에 관심을 가지고 있으며, 어떠한 노력을 기울이고 있는지를 볼 수 있었고 Naver 뿐만 아니라 여러 산학 관계에 있는 교수님들의 강연을 통해 다양한 분야에 대한 인사이트를 가지게 된 새롭고 즐거운 시간이었습니다.
정말 재미있고 깊이있는 여러 세션들이 있었는데, 그중 제게 있어 가장 흥미로웠던 주제는 <설명 가능한="" 인공지능="" 모델="" 및="" 응용=""> 파트 였습니다.
설명 가능한 인공지능 모델이란 여러 머신러닝 모델들, 특히 딥러닝이라는 분야에 있어서 모델의 결과를 설명하려 노력하는 분야를 말합니다. 저도 현재 딥러닝을 집중적으로 공부하고 있는 만큼 관심이 생긴 분야인데, 기본적으로 딥러닝은 모델의 결과가, 즉 문제에 대한 모델의 판단에 대해 어떻게 그러한 판단이 나올 수 있었는지는 블랙박스로 두게 됩니다.
문제는 이것이 mission critical한 분야에 적용되었을 때입니다. 예를들어 VCG net같은 경우 사진을 보고 대략 90%의 정확도로 사진의 인물이 동성애자라는 판단을 해냅니다. 그러나 해당 결과를 바탕으로 어떤 판단을 내릴것인가는 차별 등의 이슈로 상당히 민감한 주제일 수 있기 때문에, 소비자는 이 머신러닝의 결과로 나온 판단에 대해 왜 그런 판단이 나왔는지에 대해 질문할 권리를 가지며, 기업이 이 질문에 대해 적절한 답변을 내지 못하는 경우에는 기업의 ‘전 세계 매출의 4%’를 벌금으로 매긴다고 합니다.
이러한 문제를 극복하기 위해 최근에는 딥러닝의 히든레이어들에 많은 출력단자를 두어 모델이 판단을 내리기까지 어떤 변화가 있는지 설명해내려고 노력하고, 이미지 분석모델의 경우 LRP알고리즘이라는 방법을 통해 이미지의 어떤 부분을 통해 해당 결정을 내렸는지를 설명하려는 논문도 쏟아지고 있습니다. 자율주행 차량같은 경우에도 정확도가 조금 낮을지언정 어떤 부분을 통해 주행결정을 내렸는지를 알 수 잇는 차량의 선호도가 더 높다고 합니다. 주가 예측같은 경우에도 기존의 그래프의 어느부분이 가장 큰 영향을 미쳐서 이러한 예측결과가 나왔다라고 설명하는 모델이 큰 관심을 얻는 중입니다.
이외에도 네이버가 자랑하는 Clova 와 NSML등의 기기 및 시스템에 대한 강연 등 실제 세계와 데이터 사이언스가 어떻게 연결되는지 느껴볼 수 있었던 좋은 시간이었습니다. 저를 넓힐 수 있었던 기회를 주신 김상욱 교수님께 감사드리며 앞으로도 이런 기회가 많았으면 하는 바람입니다.